LLMEngine
class vllm.LLMEngine(model_config: ModelConfig, cache_config: CacheConfig, parallel_config: ParallelConfig, scheduler_config: SchedulerConfig, device_config: DeviceConfig, load_config: LoadConfig, lora_config: LoRAConfig | None, speculative_config: SpeculativeConfig | None, decoding_config: DecodingConfig | None, observability_config: ObservabilityConfig | None, prompt_adapter_config: PromptAdapterConfig | None, executor_class: Type[ExecutorBase], log_stats: bool, usage_context: UsageContext = UsageContext.ENGINE_CONTEXT, stat_loggers: Dict[str, StatLoggerBase] | None = None, input_registry: InputRegistry = INPUT_REGISTRY, use_cached_outputs: bool = False) [源代码]
一个接收请求并生成文本的大语言模型 (LLM) 引擎。
这是 vLLM 引擎的主类。它接收客户端的请求并从 LLM 中生成文本。它包括一个 tokenizer、一个语言模型(可能分布在多个 GPU 上)以及为中间状态分配的 GPU 内存空间(又名 KV 缓存)。该类利用 iteration-level 调度和高效的内存管理使得服务吞吐量最大化。
LLM 类包装该类进行离线批量推理,AsyncLLMEngine 类包装该类进行在线服务。
配置参数源自 EngineArgs。(参见 Engine Arguments)
参数:
-
model_config – 与 LLM 模型相关的配置。
-
cache_config – 与 KV 缓存管理相关的配置。
-
parallel_config – 与分布式执行相关的配置。
-
scheduler_config – 与请求调度程序相关的配置。
-
device_config – 与设备相关的配置。
-
lora_config (Optional) – 与服务多 LoRA 相关的配置。
-
speculative_config (Optional) – 与推测解码相关的配置。
-
executor_class – 用于管理分布式执行的模型执行器类。
-
prompt_adapter_config (Optional) – 与服务提示适配器相关的配置。
-
log_stats – 是否记录统计信息。
-
usage_context – 指定的入口点,用于收集使用信息。
DO_VALIDATE_OUTPUT: ClassVar[bool] = False 用于切换是否验证请求输出类型的标志。
中止给定 ID 的请求。
参数:
- request_id – 中止请求的 ID。
细节:
- 请参阅
Scheduler类中的abort_seq_group()。
案例
# initialize engine and add a request with request_id
# 初始化引擎并添加一个带 request_id 的请求
request_id = str(0)
# abort the request
# 中止请求
engine.abort_request(request_id)
add_request(request_id: str, inputs: str | TextPrompt | TokensPrompt | ExplicitEncoderDecoderPrompt, params: SamplingParams | PoolingParams, arrival_time: float | None = None, lora_request: LoRARequest | None = None, trace_headers: Mapping[str, str] | None = None, prompt_adapter_request: PromptAdapterRequest | None = None) → None [源代码]
add_request(request_id: str, prompt: PromptType, params: SamplingParams | PoolingParams, arrival_time: float | None = None, lora_request: LoRARequest | None = None, trace_headers: Mapping[str, str] | None = None, prompt_adapter_request: PromptAdapterRequest | None = None, priority: int = 0) → None
将请求添加到引擎的请求池中。
该请求将被添加到请求池中,并在调用 engine.step() 时由调度程序进行处理。具体的调度策略由调度器决定。
参数:
-
request_id – 请求的唯一 ID。
-
inputs – 提供给 LLM 的输入。有关每个输入格式的更多详细信息,请参阅 PromptInputs。
-
params – 用于采样或池化的参数。SamplingParams 用于文本生成。
PoolingParams用于池化。 -
arrival_time – 请求的到达时间。如果为 None,我们将使用当前的单调时间。
-
trace_headers – OpenTelemetry 跟踪头。
-
priority**–**请求的优先级。仅在优先级调度时适用。
细节:
-
如果到达时间 (arrival_time) 为 None,则将其设置为当前时间。
-
如果 prompt_token_ids 为 None,则将其设置为编码提示。
-
创建 n 个
Sequence对象。 -
从
Sequence列表中创建一个SequenceGroup对象。 -
将
SequenceGroup对象添加到调度程序中。
Example
案例
# initialize engine
# 初始化引擎
engine = LLMEngine.from_engine_args(engine_args)
# set request arguments
example_prompt = "Who is the president of the United States?"
sampling_params = SamplingParams(temperature=0.0)
request_id = 0
# add the request to the engine
# 给引擎添加请求
engine.add_request(
str(request_id),
example_prompt,
SamplingParams(temperature=0.0))
# continue the request processing
# 继续请求处理
...
do_log_stats(scheduler_outputs: SchedulerOutputs | None = None, model_output: List[SamplerOutput] | None = None, finished_before: List[int] | None = None, skip: List[int] | None = None) → None [源代码]
当没有活动请求时强制记录日志。
classmethod from_engine_args(engine_args: EngineArgs, usage_context: UsageContext = UsageContext.ENGINE_CONTEXT, stat_loggers: Dict[str, StatLoggerBase] | None = None) → LLMEngine [源代码]
从引擎参数创建 LLM 引擎。
get_decoding_config() → DecodingConfig [源代码]
获取解码配置。
get_lora_config() → LoRAConfig [源代码]
获取 LoRA 配置。
get_model_config() → ModelConfig [源代码]
获取模型配置。
获取未完成的请求数。
get_parallel_config() → ParallelConfig [源代码]
获取并行配置。
get_scheduler_config() → SchedulerConfig [源代码]
获取调度程序配置。
如果有未完成的请求,则返回 True。
has_unfinished_requests_for_virtual_engine(virtual_engine: int) → bool [源代码]
如果虚拟引擎有未完成的请求,则返回 True。
执行一次解码迭代并返回新生成的结果。
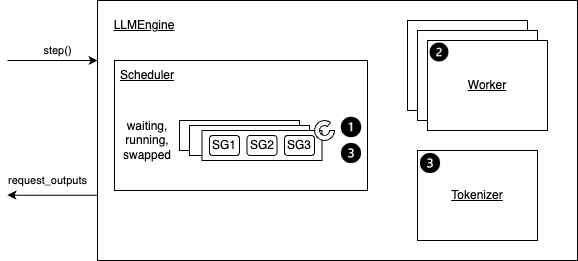 step 函数总览
step 函数总览
详细信息:
-
步骤 1:安排下一次迭代中要执行的序列,并确定要换入/换出/复制的 token 块。
-
根据调度策略,序列可能被�抢占/重新排序。
-
一个序列组 (SG) 是指由同一提示生成的一组序列。
-
-
步骤 2:调用分布式执行器来执行模型。
-
步骤 3:处理模型输出。主要包括:
-
解码相关输出。
-
根据采样参数(是否使用 _beam_search)使用模型输出更新计划的序列组。
-
释放已完成的序列组。
-
-
最后,创建并返回新的生成结果
示例
# Please see the example/ folder for more detailed examples.
# 请参阅 example/ 文件夹获得更多详细信息
# initialize engine and request arguments
# 初始化引擎和请求参数
engine = LLMEngine.from_engine_args(engine_args)
example_inputs = [(0, "What is LLM?",
SamplingParams(temperature=0.0))]
# Start the engine with an event loop
# 以事件循环启动引擎
while True:
if example_inputs:
req_id, prompt, sampling_params = example_inputs.pop(0)
engine.add_request(str(req_id),prompt,sampling_params)
# continue the request processing
# 持续请求过程
request_outputs = engine.step()
for request_output in request_outputs:
if request_output.finished:
# return or show the request output
# 返回或显示请求输出
if not (engine.has_unfinished_requests() or example_inputs):
break